데이터독에서 권장하는 로그 모듈을 사용하면 알아서 APM - LOG 연동이 가능하다.
NodeJS의 경우 winston, Java의 경우 Log4j/Logback 등이 있다.
NestJS를 사용할 경우 nestjs-pino를 로그 모듈로 사용해도 잘 동작한다.
실제 dd-trace 모듈을 열어보면 winston 외 다른 로그 모듈도 인티그레이션 되어 있다.
netstjs-pino의 경우 pino에 종속적이라 사용이 가능한 것으로 보인다.


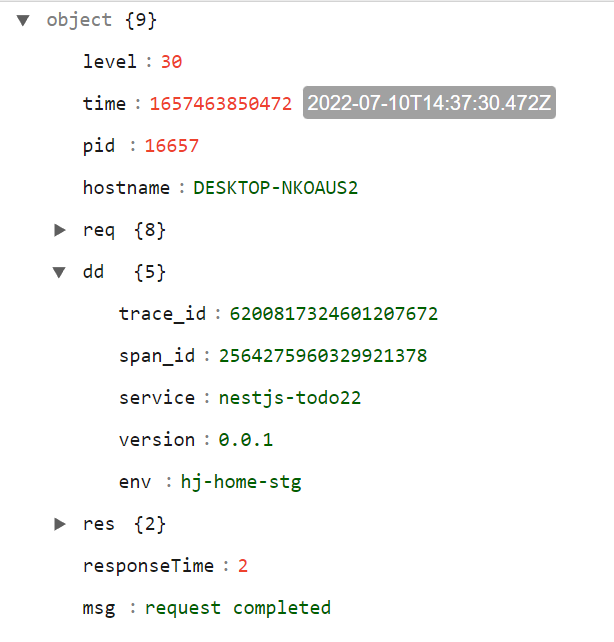
서버에서 로그를 생성하면 trace_id, span_id 값이 로그에 찍힌 것을 볼 수 있다.
{"level":30, ... ,"dd": {"trace_id": xxxx, "span_id": xxx}, "res": {"responseTime": 2, "msg": "request completed"}
데이터독과 인티그레이션 된 로그 모듈(Json)을 사용했다면 데이터독은 자동으로 로그 파이프라인을 만들어준다.
파이프라인은 인제스터 된 로그를 데이터독이 이해할 수 있게 인덱싱 하는 작업이다. 파이프라인은 다양한 프로세서들로 구성되었으며 가장 중요한 부분은 로그를 Json 형식으로 만들어주는 Grok 파서다.
기본적으로 데이터독은 Json 포맷으로 로그를 인덱싱 한다.

만약 파이프라인이 만들어지지 않았다면 Browse Pipeline Library를 통해 사용하는 플랫폼의 로그 포맷을 찾아본다. 없다면 파이프라인을 직접 구성해야 한다.
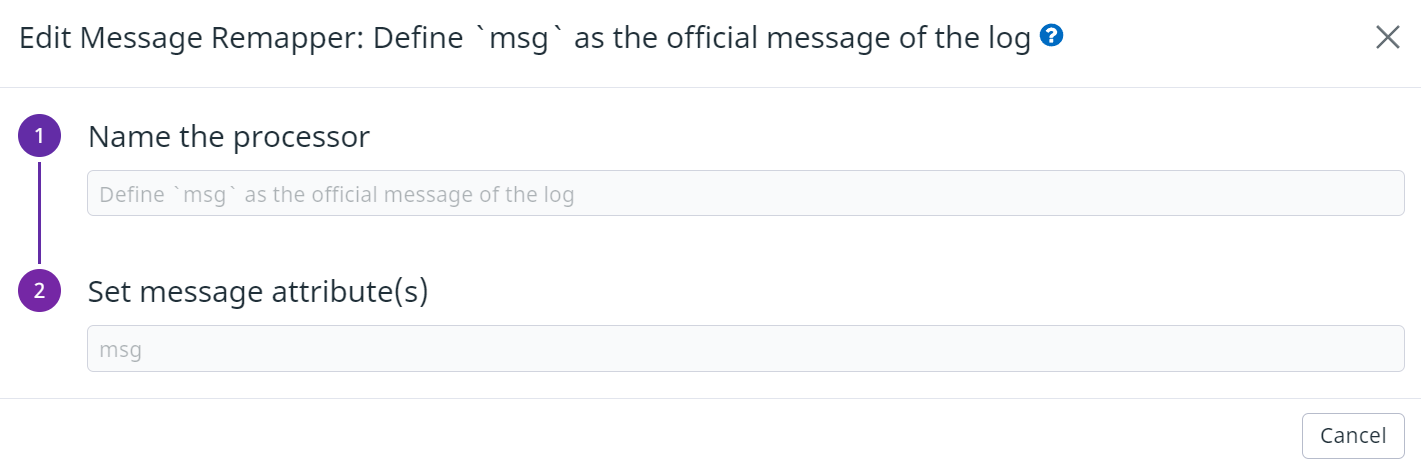
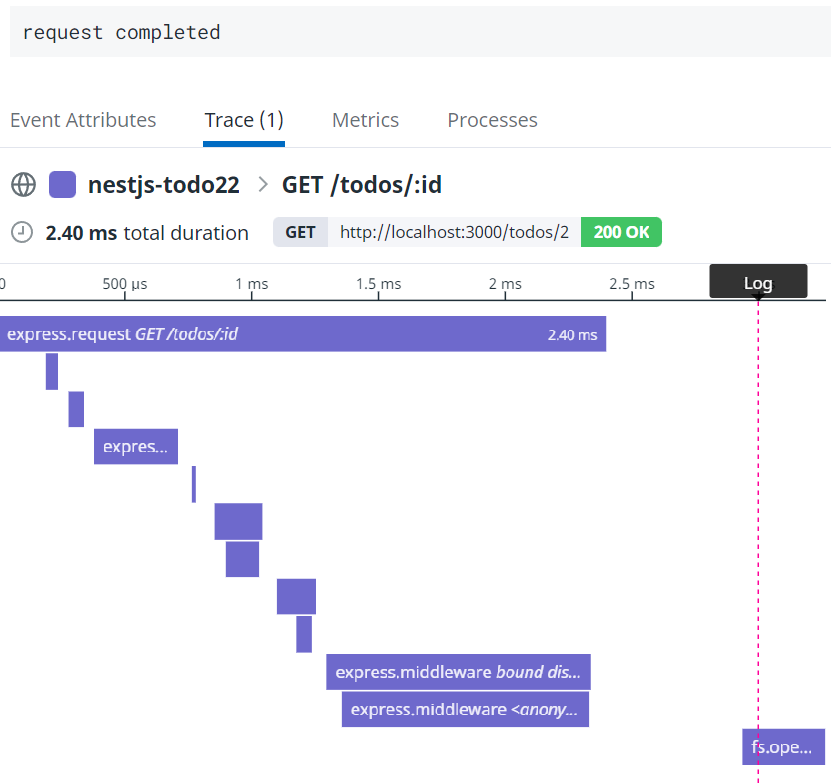
예를 들어 Message Remapper는 데이터독 로그 콘솔에서 이벤트 어트리뷰트 상단 메시지를 지정한다. 로그에서 msg 키 값을 로그의 공식 메시지로 지정하는 것이다.
아래 그림과 같이 {"msg": "request completed"} 가 데이터톡 로그 콘솔 어트리뷰트 상단에 보이는 것을 알 수 있다.

파이프라인을 통해 중요한 로그 키값을 지정할 수도 있고 Date 포맷을 변경시키거나, 로그 레벨을 지정하거나 여러 작업이 가능하다.
Grok 파서는 앞서 설명했듯이 다양한 로그 포맷들을 Json 형태로 변경해준다. 이미 netstjs-pino 모듈로 Json 포맷으로 로그가 변경되었기 때문에 지금은 큰 의미는 없다.


다양한 파이프라인 프로세서를 통해 로그 분석의 중요 정보들을 재정의할 수 있다.

APM 연동과 좀 더 로그를 잘 사용하기 위해서 Trace ID, Service, Status, Message, Date Remapper를 사용할 수 있으며, env, version 등 중요 태그도 Remapper(인덱싱)로 지정할 수 있다.
이 부분은 Browse Pipeline Library에서 이미 인티그레이션 된 서비스를 보면 좀 더 이해하기 쉽다.
파이프라인 작업이 끝나면 그럼 LOG - APM(Trace) 와 연동된다.

인티그레이션 된 로그에 내용을 변경하거나, 인티그레이션 되지 않은 로그를 사용한다면 위와 같은 파이프라인 작업을 직접 구성해줘야 한다.
가령 Json 형태가 아닌 아래와 같은 로그가 데이터독에 인제스터 되었을 때는 파이프라인 프로세스를 구성해야 한다.
ERROR - 2022-07-12 13:20:25 --> {"message":"datadog_healthcheck","dd_log":"[dd.trace_id=7089576885492005582 dd.span_id=9223372036854775807]"}
DEBUG - 2022-07-14 21:14:23 --> {"message":"Helper loaded: form_helper","dd":"[dd.trace_id=9223372036854775807 dd.span_id=9223372036854775807]"}
DEBUG - 2022-07-11 19:15:30 --> Helper loaded: url_helper
그 전에 먼저 기본적인 Grok 파서를 연습해보자.
https://docs.datadoghq.com/logs/log_configuration/parsing/?tabs=matchers
rule은 내림차순으로 적용되며, 매칭이 되지 않으면 다음 rule로 넘어간다.

- String -> word, data(스페이스, 개행 포함, .*와 같음)
- Number -> number, integer
- 공백의 개수가 파악되지 않을 때 -> \s+
- 특수 기호가 있을 때 -> \ (e.g "[" 가 있을 때는 \[ 형식)
- 문장이 있거나 or 없거나 -> (%{"data:user.familyname"} )?
- Key/Value 형식 -> %{data::keyvalue("=", "/:", ...)} / Json 형식 -> %{data::json}
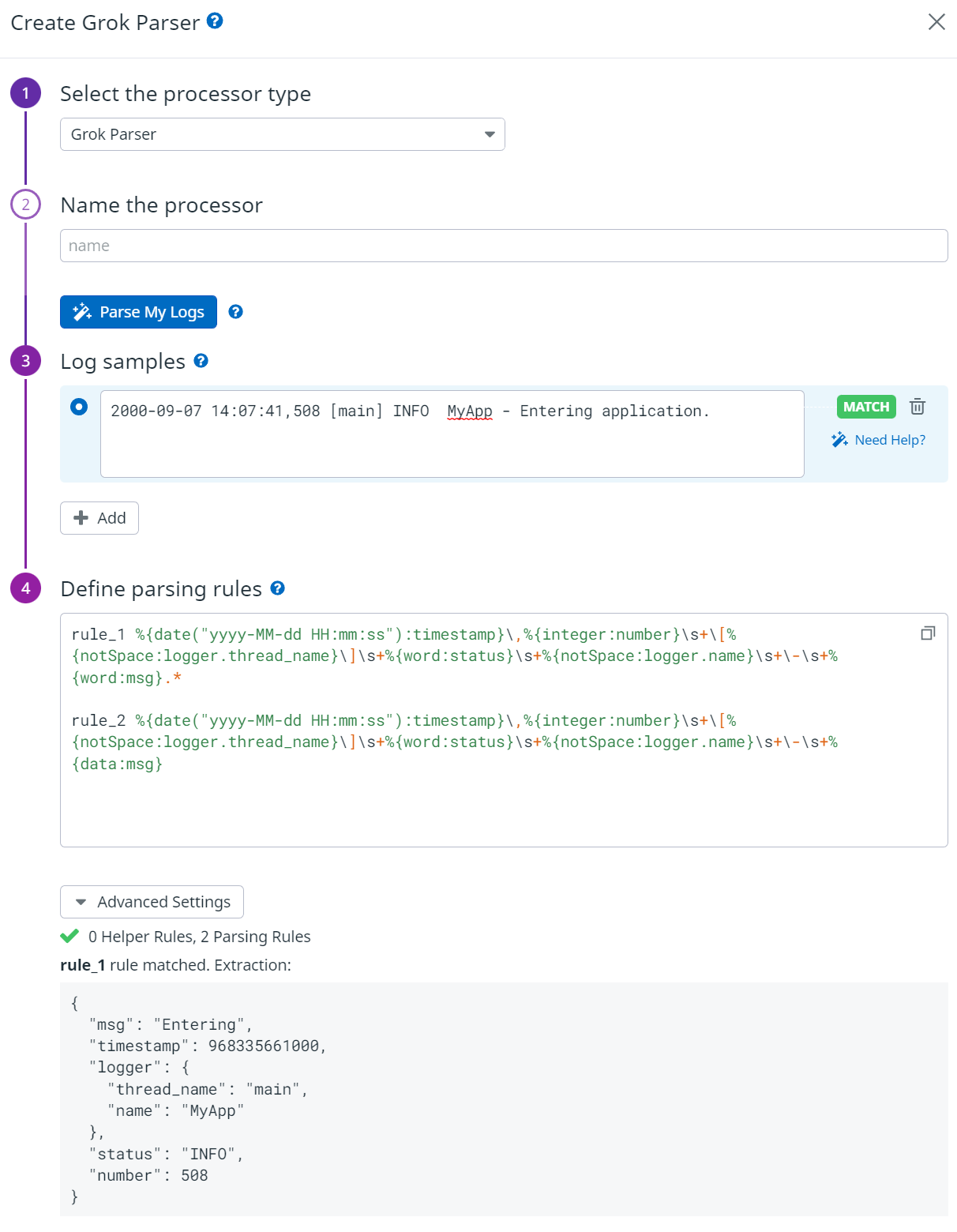
각 룰을 엮어서도 사용할 수 있다.

그럼 이제 아래 세 가지 다른 형태의 로그를 Grok 한 프로세스로 처리해보자.
Grok 프로세서를 여러 개 만들어 나눠서도 처리는 가능하다. 정규식도 사용 가능하다.
ERROR - 2022-07-12 13:20:25 --> {"message":"datadog_healthcheck","dd_log":"[dd.trace_id=7089576885492005582 dd.span_id=9223372036854775807]"}
DEBUG - 2022-07-14 21:14:23 --> {"message":"Helper loaded: form_helper","dd":"[dd.trace_id=9223372036854775807 dd.span_id=9223372036854775807]"}
DEBUG - 2022-07-11 19:15:30 --> Helper loaded: url_helper
2가지 Rule과 4가지 Helper Rule을 통해 통해 위 다른 형태의 로그를 하나의 Grok 프로세스로 처리할 수 있다. 핵심은 Json 으로 변환한 값을 다시 받아서 재정의 하는 것이다. (%(data::json).\"message\ ~~~ 구문)

그리고 로그 level, trace_id, msg 등 리매퍼 프로세서를 추가한다.

파이프라인 작업 이전에는 아래 그림과 같이 정상적으로 인덱싱 되지 않고 있었다.

파이프라인 작업을 통해 정상적으로 인덱싱 되는 것을 확인할 수 있다.
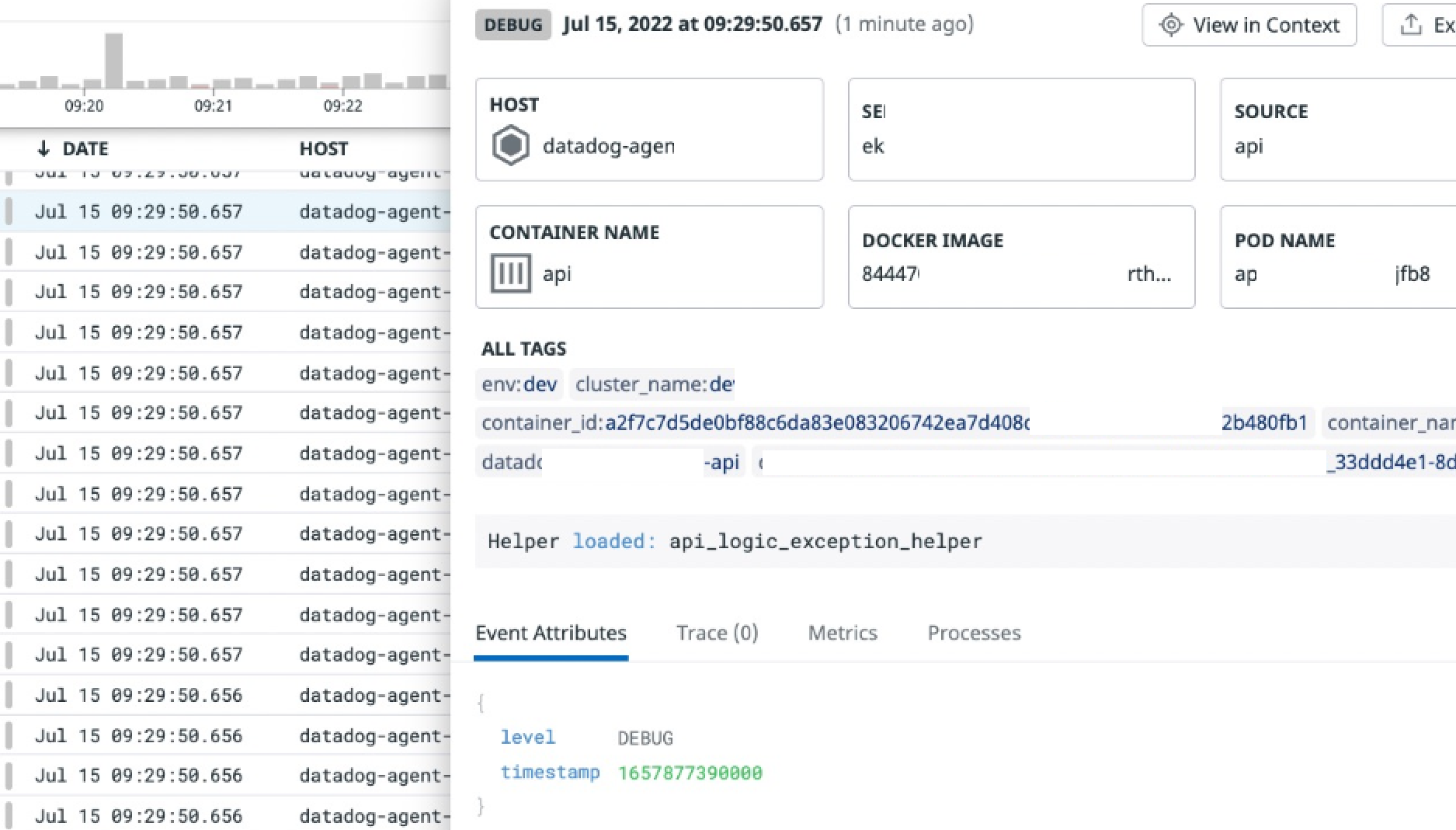
정상적으로 로그가 인덱싱 되면 데이터독 로그 콘솔에서는 리매핑 된 어트리뷰트는 Event Atrributes 항목에서 보이지 않는다.
msg는 로그 상단에 출력되고, trace_id/span_id는 보이지 않으며, 로그 레벨은 DEBUG로 지정된 것을 알 수 있다.
막상 Grok 파서를 사용하면 생각보다 어려움이 있기 때문에 어느정도 연습이 필요하다.
기본은 https://learn.datadoghq.com/enrol/index.php?id=36 데이터독 러닝센터에서 연습을 추천한다. 15일 간 트라이얼 계정이 주어지며 Log 파이프라인 뿐만 아니라 다양한 코스가 있다.
'Log' 카테고리의 다른 글
| Datadog Log Archives S3와 Amazon Athena 활용 (1) | 2024.09.25 |
|---|---|
| Datadog 로그 지연 시간 확인 (0) | 2022.10.19 |
| 데이터독 K8s helm 사용 시, 로그 제외 (0) | 2022.07.09 |

